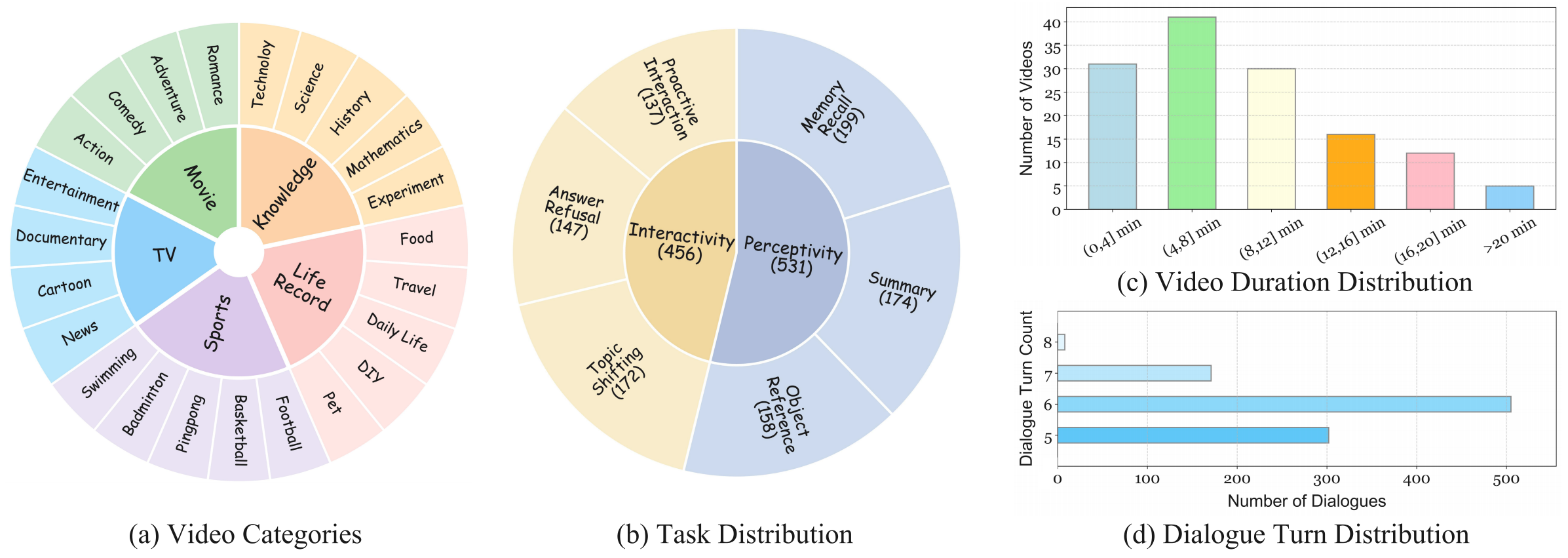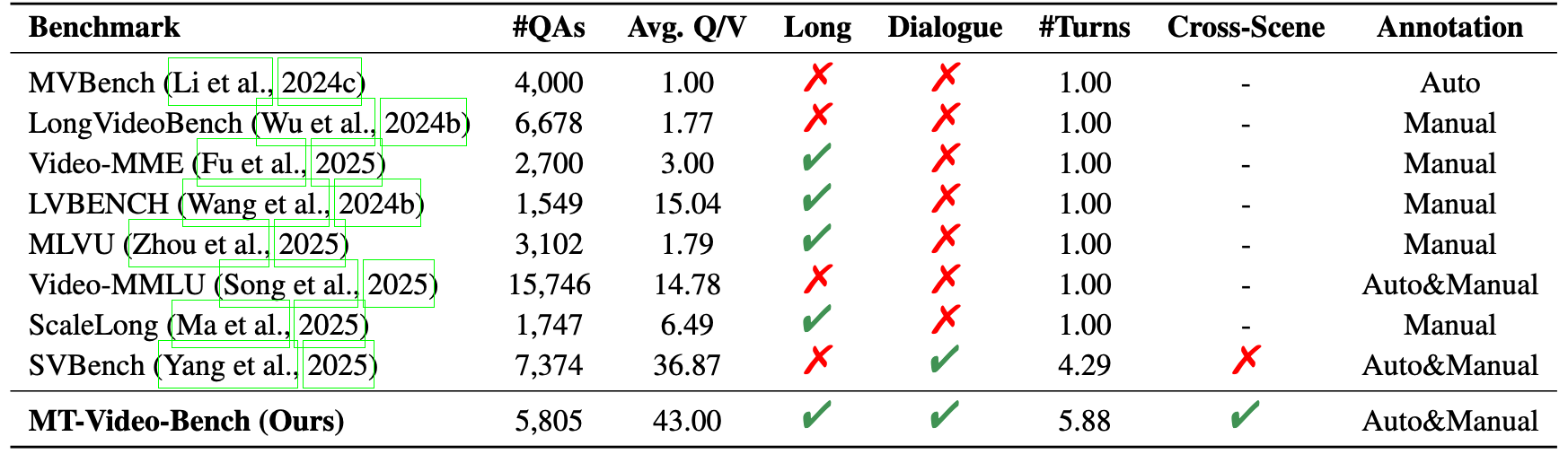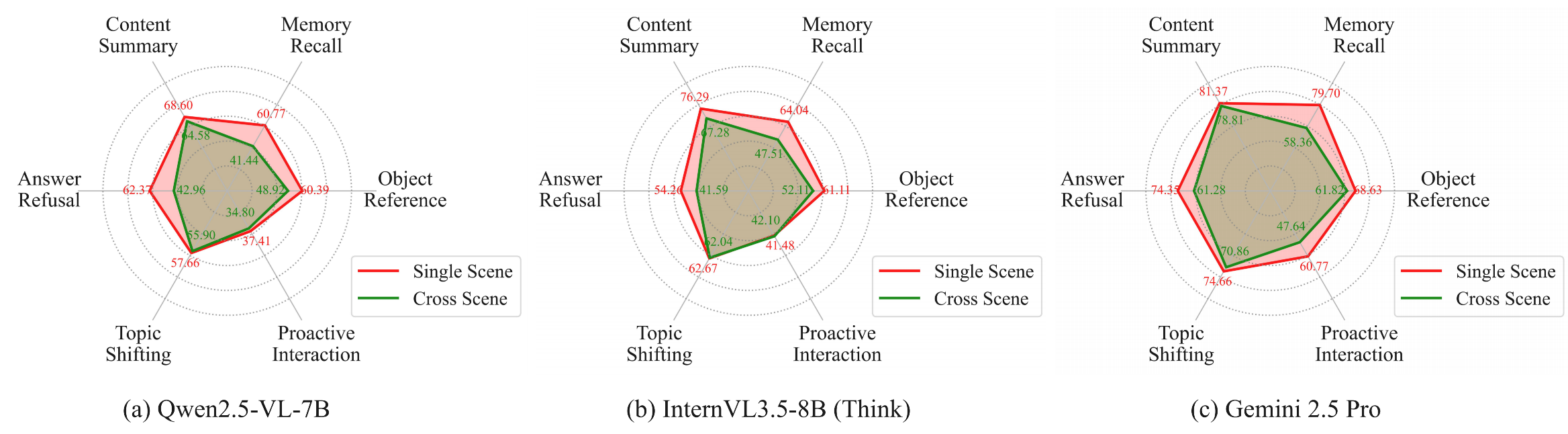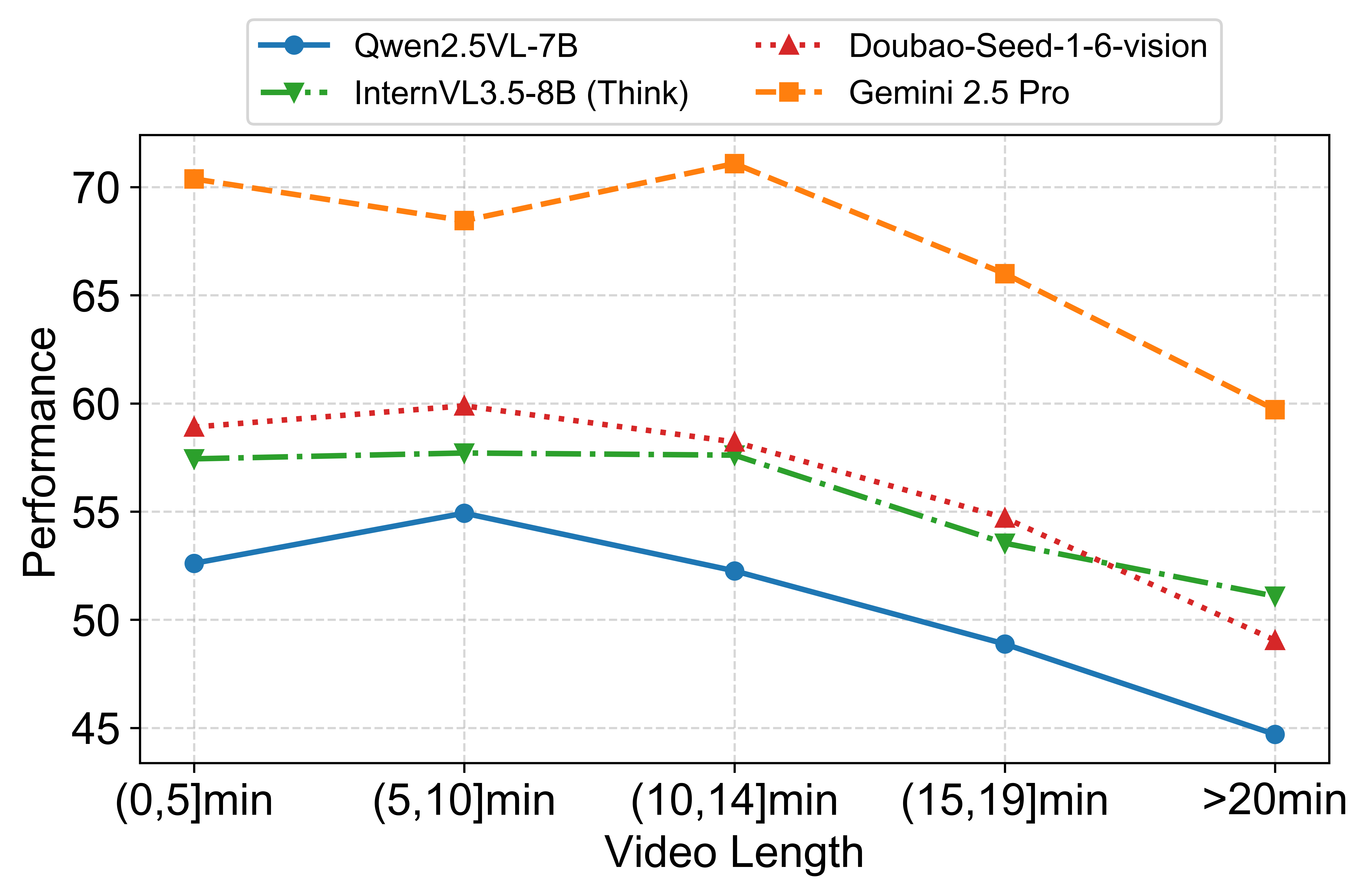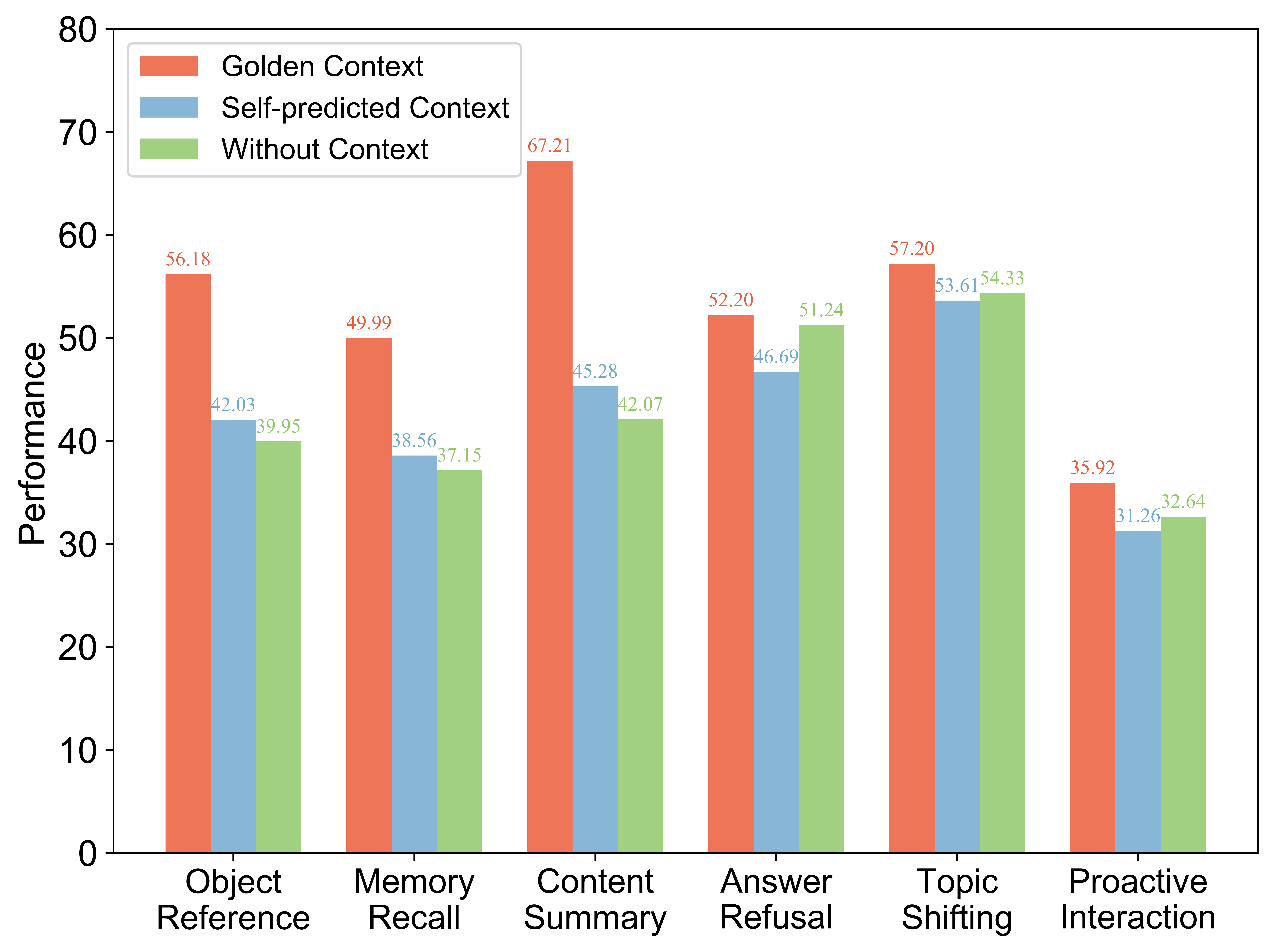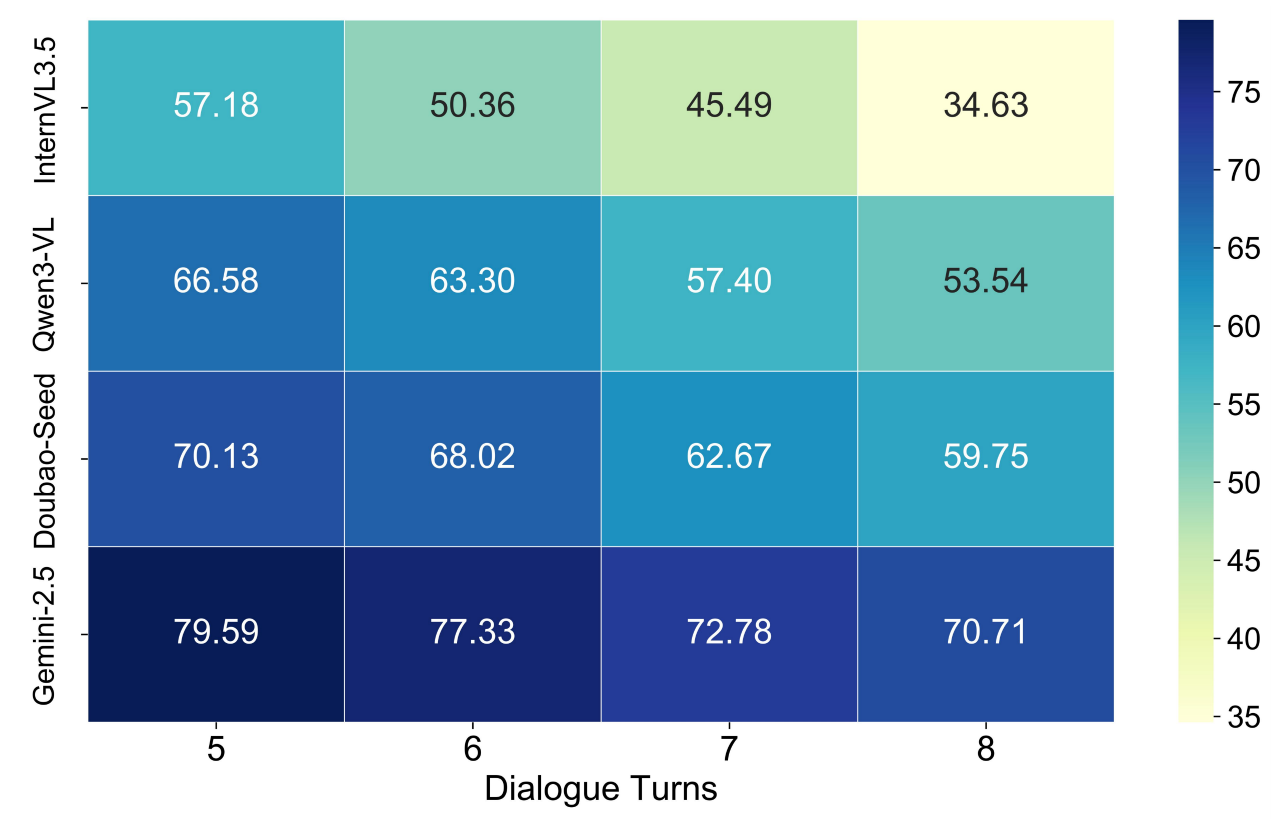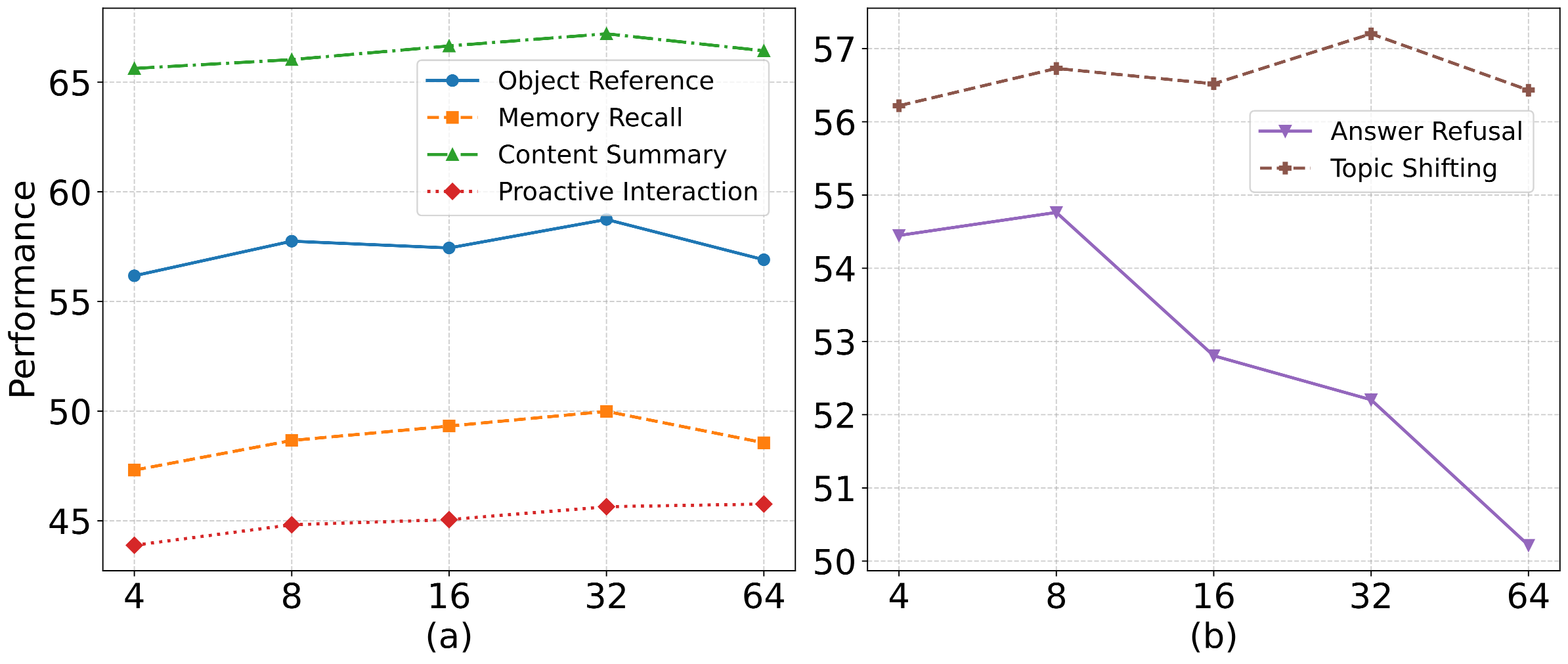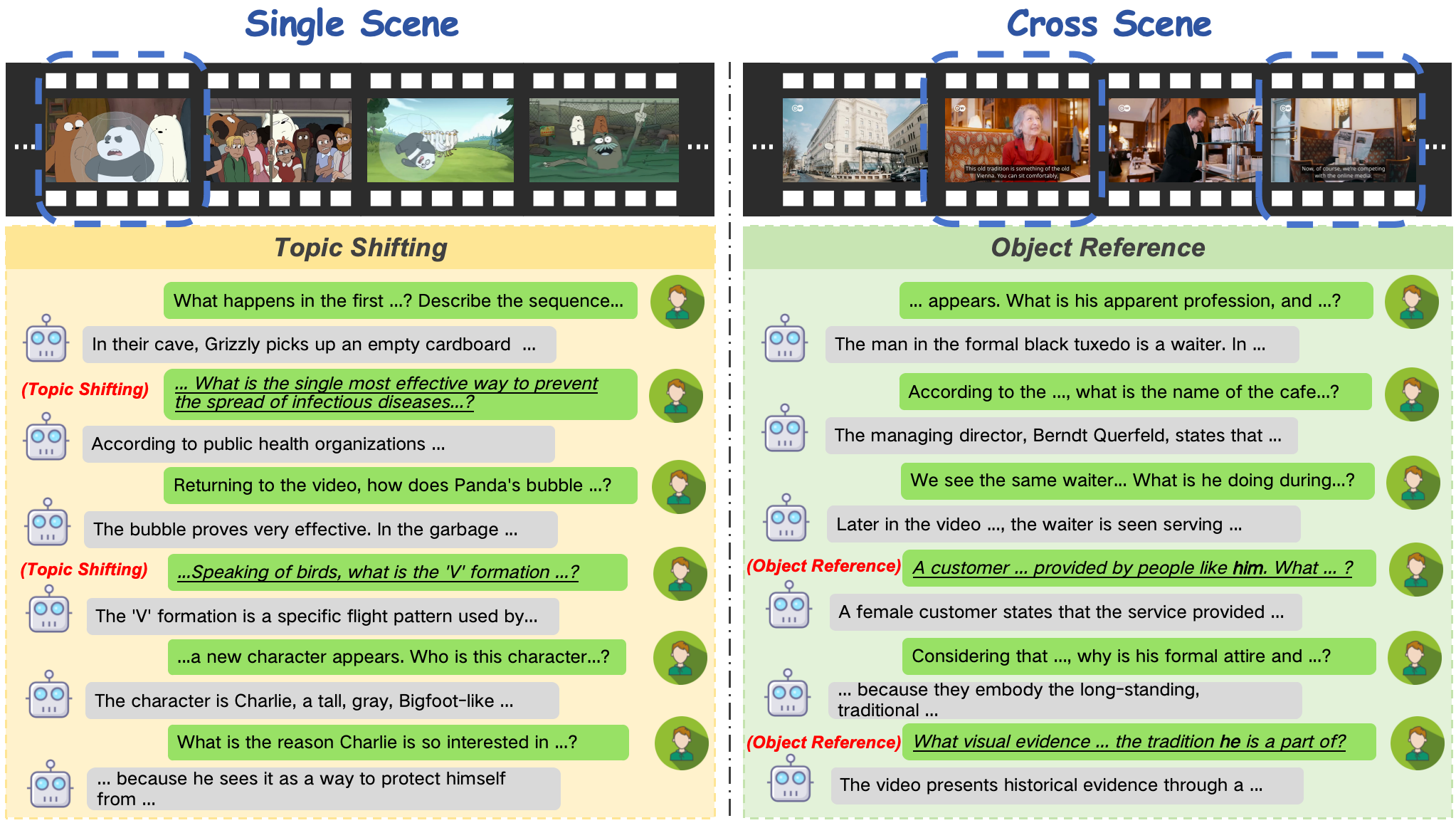
OR: Object Reference MR: Memory Recall CS: Content Memory AR: Answer Refusal TS: Topic Shifting PI: Proactive interaction
By default, this leaderboard is sorted by overall. To view other sorted results, please click on the corresponding cell.
| # | Models | Overall (%) | Perceptivity (%) | Interactivity (%) | ||||
|---|---|---|---|---|---|---|---|---|
| OR | MR | CS | AR | TS | PI | |||
| - | Gemini 2.5 Pro | 76.95 | 71.63 | 72.45 | 93.71 | 57.74 | 89.67 | 76.50 |
| - | Gemini 2.5 Flash | 69.90 | 64.07 | 67.23 | 92.45 | 47.50 | 83.17 | 64.98 |
| - | Doubao-Seed-1.6-250615 | 67.40 | 53.82 | 57.20 | 93.21 | 55.57 | 81.30 | 63.30 |
| - | Qwen3-VL-32B-Thinking | 68.57 | 58.50 | 59.11 | 93.21 | 52.93 | 81.72 | 65.93 |
| Qwen3-VL-32B-Instruct | 67.84 | 55.57 | 59.94 | 91.40 | 50.48 | 82.88 | 66.80 | |
| InternVL3.5-38B (Think) | 58.50 | 52.03 | 48.51 | 77.39 | 37.84 | 67.87 | 67.34 | |
| InternVL3.5-38B (No Think) | 53.74 | 47.34 | 42.85 | 66.99 | 34.92 | 62.23 | 68.09 | |
| Qwen3-VL-8B-Thinking | 65.98 | 54.78 | 58.21 | 90.97 | 45.35 | 78.01 | 68.59 | |
| Qwen3-VL-8B-Instruct | 62.96 | 53.20 | 54.48 | 90.25 | 44.87 | 73.45 | 61.49 | |
| InternVL3.5-8B (Think) | 58.36 | 50.70 | 51.58 | 73.83 | 38.83 | 68.74 | 66.47 | |
| MiniCPM-V4.5 | 56.84 | 54.53 | 48.57 | 77.86 | 39.46 | 61.29 | 59.35 | |
| Qwen2.5-VL-7B | 54.92 | 47.59 | 44.57 | 77.26 | 43.16 | 60.38 | 56.57 | |
| LLaVA-Video-7B | 53.76 | 43.00 | 41.75 | 82.38 | 39.07 | 59.38 | 56.99 | |
| LLaVA-OneVision-7B | 52.97 | 42.66 | 39.97 | 82.11 | 36.02 | 58.98 | 58.09 | |
| InternVL3.5-8B (No Think) | 52.20 | 45.61 | 39.01 | 63.59 | 33.01 | 60.52 | 71.46 | |
| MiniCPM-o | 50.39 | 46.66 | 39.79 | 74.80 | 27.20 | 56.26 | 57.64 | |
| VideoChat-Flash-7B | 46.02 | 41.53 | 38.28 | 69.16 | 24.67 | 51.37 | 51.12 | |
| LLaVA-NeXT-Video-7B | 45.66 | 38.87 | 32.45 | 79.09 | 23.79 | 42.57 | 57.16 | |
| VideoLLaMA3-7B | 38.10 | 41.59 | 31.15 | 47.88 | 29.26 | 35.53 | 43.20 | |
| InternVideo2.5-8B | 38.09 | 31.64 | 34.61 | 41.56 | 25.55 | 50.54 | 44.66 | |
| Qwen3-VL-4B-Thinking | 62.96 | 52.18 | 55.26 | 91.37 | 41.67 | 72.00 | 65.31 | |
| Qwen3-VL-4B-Instruct | 59.15 | 49.29 | 46.74 | 83.66 | 52.99 | 65.34 | 56.88 | |
| InternVL3.5-4B (Think) | 54.58 | 47.80 | 45.02 | 70.52 | 31.82 | 62.39 | 69.96 | |
| InternVL3.5-4B (No Think) | 49.50 | 41.87 | 40.31 | 60.56 | 28.14 | 55.71 | 70.43 | |